
This page covers functions that can be used to make queries involving a text search. Text search functions operate on fields that have been tokenized into arrays of strings. If your data isn’t already tokenized, you can do so by creating an Ingest Transformation with a variety of string functions including:
You can also combine and consolidate the output of these functions using a combination of ARRAY_CONCAT and ARRAY_DISTINCT. Here's an example ingest transformation leveraging these functions:
SELECT
text,
ARRAY_DISTINCT(ARRAY_CONCAT(TOKENIZE(text), PREFIXES(text, 3))) AS search_array
FROM
_input
With the search array you can now use ARRAY_CONTAINS or ARRAY_CONTAINS_ANY for exact match text search scenarios. For scored text search, the SEARCH function is designed for sophisticated term matching queries.
SEARCH
There are a few limitations to the SEARCH function to keep in mind:
SEARCHonly works in theWHEREclause of a query on a collection. It does not work if the target of a query is a subquery or aJOIN,
and it does not work in other parts of the query outside of theWHEREclause.SEARCHmay be combined with other operators and functions in the sameWHEREclause as long as they are part of a conjunction usingANDoperators.
The collection data used in the following SQL queries contains four documents:
+------+-------------------------------------------------------------------------+
| id | words |
|------+-------------------------------------------------------------------------|
| doc1 | ['The', 'quick', 'brown", 'fox', 'jumps', 'over', 'the', 'lazy', 'dog'] |
| doc2 | ['hello', 'world', 'goodbye', 'world'] |
| doc3 | ['cat', 'dog', 'fox'] |
| doc4 | ['hello", 'goodbye'] |
+------+-------------------------------------------------------------------------+
SEARCH(term_matcher[, term_matcher]*) [OPTION(match_all=false)] Return documents that satisfy all of the term matchers (by default), or at least one of the term matchers (with OPTION(match_all=false)). Term matchers are arbitrary SQL boolean expressions, optionally boosted. The score of the match is the sum of the boost values (default 1) for all terms that matched. For searches that include proximity ranges (see below), each proximity range also adds to the score a proximity score that depends on the longest consecutive match.
/*
In this example, `doc2` got 2 points, 1 point each for the occurrence of words
['hello', 'world']. No other document contains both 'hello' and 'world' in the
field words.
*/
SELECT
_id,
words,
score() score
FROM
data
WHERE
search(
has_term(words, 'hello'),
has_term(words, 'world')
)
ORDER BY
score() DESC
SCORE
If you use the SEARCH function, SCORE() becomes available as a function with no arguments, which returns the score of the match. The remainder of this page goes into more detail about how to use the SEARCH function.
Term Matcher Functions
In the Term Matcher Functions page, we describe how to use SEARCH with the supported term matchers.
List of functions defined in Term Matcher Functions page:
| Function | Description |
|---|---|
BOOST(boost_value, term) | Set the boost value (a positive floating point value) for a specific search term so that the term contributes the specified value. Unboosted terms contribute a default score of 1.0. |
CONTAINS(field, search_string[, locale]) | Tokenize the given search string in the given locale (default: en_US) and create a proximity range from the terms. |
HAS_TERM(field, term) | A term matcher that lets you search documents where the specified field contains the specified term. Upon a successful match, this matcher contributes a score of 1. Note that following sample queries use collection data described at the top of this page. |
PROXIMITY(term_matcher[, term_matcher]*) | Create a proximity range matcher using the given term matchers. The term matchers will contribute 1 point to the final score, just like other term matchers in the SEARCH query. But the proximity range mather will also contribute a proximity score that depends on the longest consecutive match. The longest consecutive match is the longest sequence of N consecutive terms such that: - term at index T satisfies term matcher at index P - term at index T+1 satisfies term matcher at index P+1 - ... - term at index T+N-1 satisfies term matcher at index P+N-1 Based on the length N of the longest consecutive match, the proximity score is computed as ((N - 1) / 2). |
PROXIMITY_BOOST(boost_value, proximity_range) | Set the proximity range boost value (a positive floating point value) for the given specific search proximity range. This affects the proximity range's contribution to the score i.e. the proximity score, but not the contributions of the individual terms in the range. proximity_range must be a proximity range created using either PROXIMITY or CONTAINS. |
SEARCH(term_matcher[, term_matcher]*) [OPTION(match_all=false)] | Return documents that satisfy all of the term matchers (by default), or at least one of the term matchers (with OPTION(match_all=false)). Term matchers are arbitrary SQL boolean expressions, optionally boosted. The score of the match is the sum of the boost values (default 1) for all terms that matched. For searches that include proximity ranges (see below), each proximity range also adds to the score a proximity score that depends on the longest consecutive match. |
BM25
BM25 is currently in Private Preview. Please contact Rockset Support to enable this feature.
BM25(terms, field) [OPTION(k=1.6)] [OPTION(b=0.75] executes the Okapi BM25 ranking function used to estimate the relevance of documents given a set of terms. BM25 leverages a bag-of-words approach by ranking documents based on the search terms appearing in each document, regardless of term proximity.
Given a query Q, containing key words q_1, ..., q_n, the BM25 score of document follows:
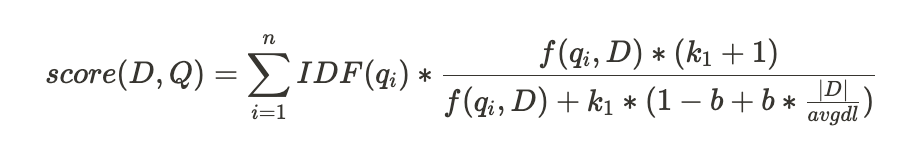
f(q_i, D)represents the number of times that the termq_ioccurs in documentD.|D|is the length of documentDin words.avgdlis the average length of documents in the given collection.k_1andbare free parameters usually chosen ask_1 ∈ [1.2, 2]andb=0.75.IDF(q_i)is the inverse document frequency (IDF) weight of query termq_i.
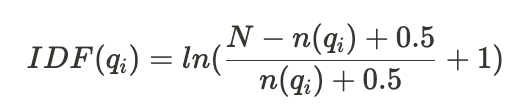
Nrepresents the total number of documents in the collection.n(q_i)is the total number of documents containingq_i.
In the case of BM25, we compute and store f(q_i, D) as a well-known attribute. Thus, for each term-document pair in the search index, we track the frequency of the term within the document. We also track two values at the collection level: the total number of documents N and a running sum of the total document length, which allows us to easily compute the average document length avgdl. Given the use of well-known attributes and collection-level metadata, we can efficiently calculate BM25 scores for individual documents with minimal computational overhead.
SELECT
_id,
words,
BM25(['hello', 'world'], words) as bm25_score
FROM
data
ORDER BY bm25_score DESC